
Introduction
Large language models (LLMs) are the powerhouses behind groundbreaking advancements in artificial intelligence. But here’s the catch: high-quality data is expensive, time-consuming to curate, and often riddled with privacy concerns. NVIDIA’s Nemotron-4 340B is a comprehensive open-source toolkit that helps researchers and developers to generate their own synthetic training data.
Benefits:
- Easier and cheaper training for LLMs, especially in areas with limited real-world data.
- More control over the training data, potentially reducing bias and improving accuracy.
- Faster development cycles for LLMs.
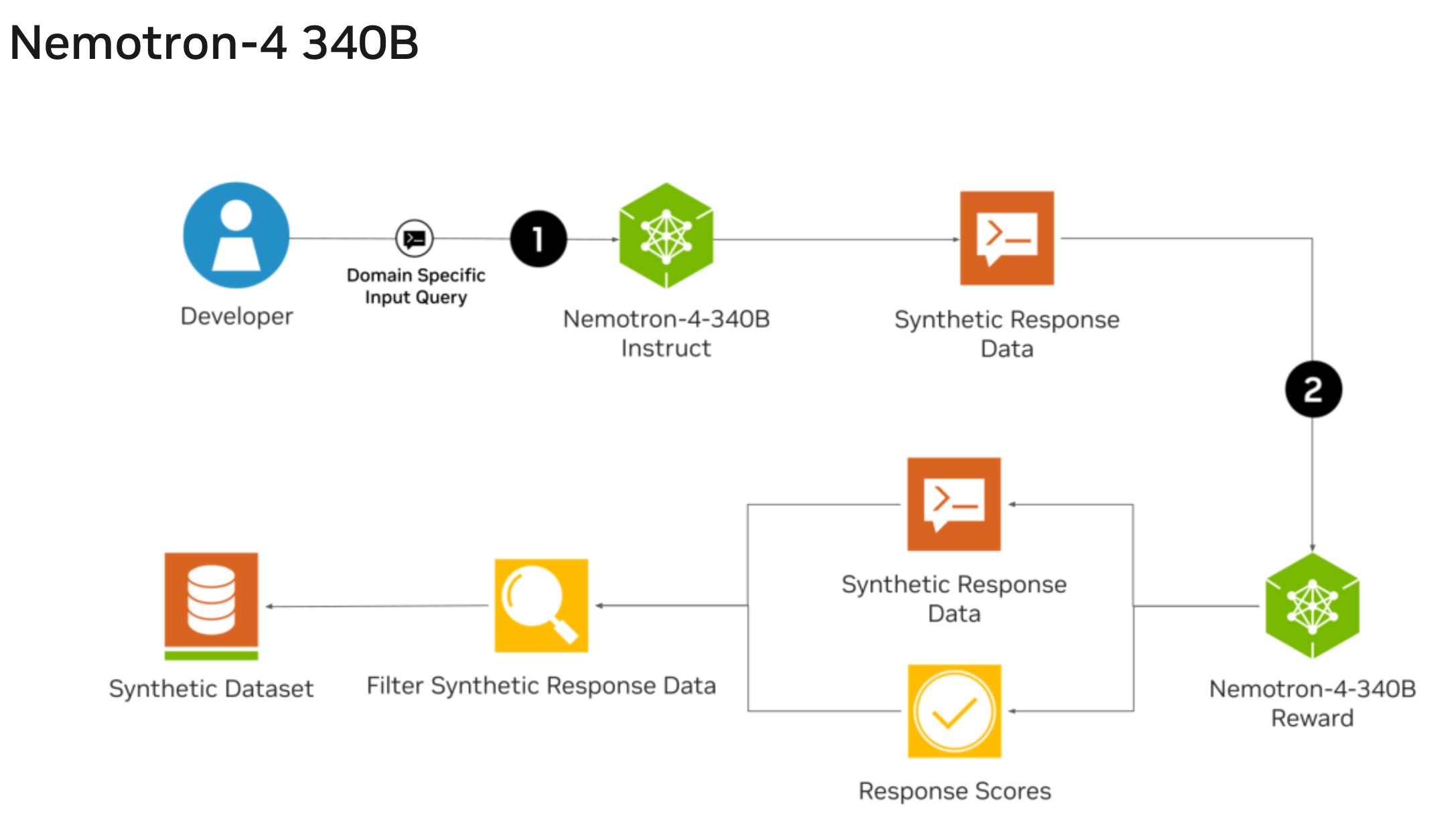
Breaking Down the Nemotron-4 340B Pipeline
Nemotron-4 340B has a three-pronged approach designed for maximum efficiency. Here’s a closer look at each component:
Nemotron-4-340B-Base: This is a massive 340 billion parameter LLM pre-trained on a colossal dataset of 9 trillion tokens. It encompasses a diverse range of information, including text in over 50 languages and code from 40+ programming languages.
Nemotron-4-340B-Instruct: This component guides the data generation process. You provide instructions outlining the specific type of data you need, and Nemotron-4-340B-Instruct crafts synthetic samples that align with your requirements.
Nemotron-4-340B-Reward: Not all synthetic data is created equal. The reward model acts as a quality control mechanism, filtering out subpar outputs and ensuring the generated data adheres to the desired standards.
The beauty of Nemotron-4 340B lies in its accessibility. Released under the permissive NVIDIA Open Model License Agreement, anyone can use it for free.
An Example
Let’s imagine you are a developer at a tech company working on a multilingual customer support chatbot. You want the chatbot to handle various customer inquiries in multiple languages with accurate, context-aware responses.
Here’s how Nemotron-4 340B can help:
Step 1: Nemotron-4-340B-Base
You start with Nemotron-4-340B-Base, the foundational large language model (LLM). This model has been pre-trained on a vast dataset of 9 trillion tokens, covering text in over 50 languages and code from more than 40 programming languages. This gives it a broad and deep understanding of language, context, and various programming needs.
Example:
You input a sample query in Spanish: “¿Cómo puedo restablecer mi contraseña?”
Nemotron-4-340B-Base Output:
“Para restablecer su contraseña, haga clic en ‘Olvidé mi contraseña’ en la pantalla de inicio de sesión y siga las instrucciones enviadas a su correo electrónico.”
Step 2: Nemotron-4-340B-Instruct
Next, you use Nemotron-4-340B-Instruct to generate synthetic data. You provide it with specific instructions to create a variety of customer support queries and responses in different languages.
Instruction Example:
“Generate customer support queries and responses for password reset issues in Spanish, French, and Japanese.”
Nemotron-4-340B-Instruct Output:
Spanish:
- Query: “¿Cómo puedo cambiar mi contraseña?”
- Response: “Para cambiar su contraseña, vaya a ‘Configuración’ y seleccione ‘Cambiar contraseña’.”
French:
- Query: “Comment puis-je réinitialiser mon mot de passe?”
- Response: “Pour réinitialiser votre mot de passe, cliquez sur ‘Mot de passe oublié’ sur l’écran de connexion.”
Japanese:
- Query: “パスワードをリセットするにはどうすればいいですか?”
- Response: “ログイン画面で「パスワードを忘れた」をクリックし、メールで送信された指示に従ってください。”
Step 3: Nemotron-4-340B-Reward
Finally, you employ Nemotron-4-340B-Reward to ensure the quality of the generated synthetic data. This reward model evaluates the outputs and filters out those that do not meet your quality standards, ensuring that only high-quality, contextually accurate data is used.
Quality Check Example:
The reward model reviews the generated responses and discards any that are unclear, incorrect, or not contextually appropriate. It may discard a response if it fails to accurately guide a user through the password reset process.
Filtered Output:
- Spanish:
- Query: “¿Cómo puedo cambiar mi contraseña?”
- Response: “Para cambiar su contraseña, vaya a ‘Configuración’ y seleccione ‘Cambiar contraseña’.”
French:
- Query: “Comment puis-je réinitialiser mon mot de passe?”
- Response: “Pour réinitialiser votre mot de passe, cliquez sur ‘Mot de passe oublié’ sur l’écran de connexion.”
Japanese:
- Query: “パスワードをリセットするにはどうすればいいですか?”
- Response: “ログイン画面で「パスワードを忘れた」をクリックし、メールで送信された指示に従ってください。”
By leveraging the three components of Nemotron-4 340B, you efficiently create a robust dataset for training your multilingual customer support chatbot, ensuring it provides accurate and helpful responses across different languages.
This pipeline’s accessibility under the NVIDIA Open Model License Agreement means you can utilize it without additional costs, making it an excellent resource for your development needs.
Read More: Top 5 Courses to Launch Your AI Journey – techovedas
Head-to-Head with GPT-4
The question on everyone’s mind: how does Nemotron-4 340B stack up against the reigning champion, GPT-4? Here’s what we know so far:
- Competitive Performance: Early benchmarks suggest Nemotron-4 340B performs competitively with GPT-4 on various tasks. This is impressive considering it relies heavily on synthetic data, while GPT-4 likely utilizes a mix of real-world and synthetic data.
- Specific Strengths: Nemotron-4 340B shines in tasks requiring factual accuracy and logical reasoning. Some users report it excels at answering challenging questions with surprising precision.
- Areas for Improvement: While Nemotron-4 340B excels in factual tasks, reports suggest it might lag behind GPT-4 in areas like creative writing or generating different artistic styles.
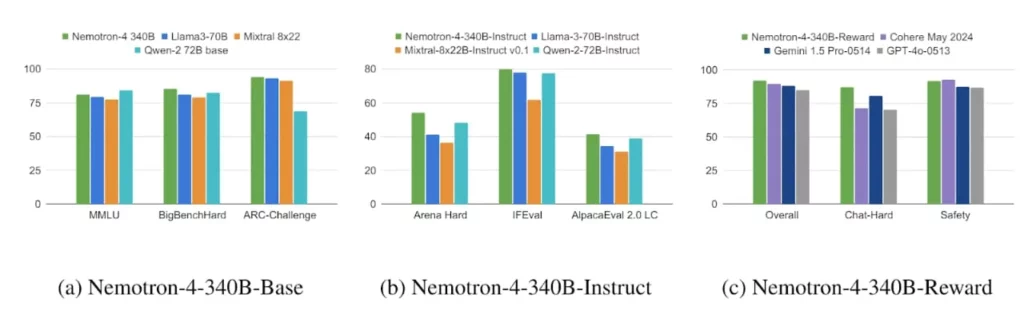
Image Credits: Nvidia
The takeaway: It’s not a clear-cut victory for either model. Nemotron-4 340B delivers impressive performance for factual tasks and boasts the advantage of open-source synthetic data generation. GPT-4, on the other hand, might still hold the edge in creative endeavors.
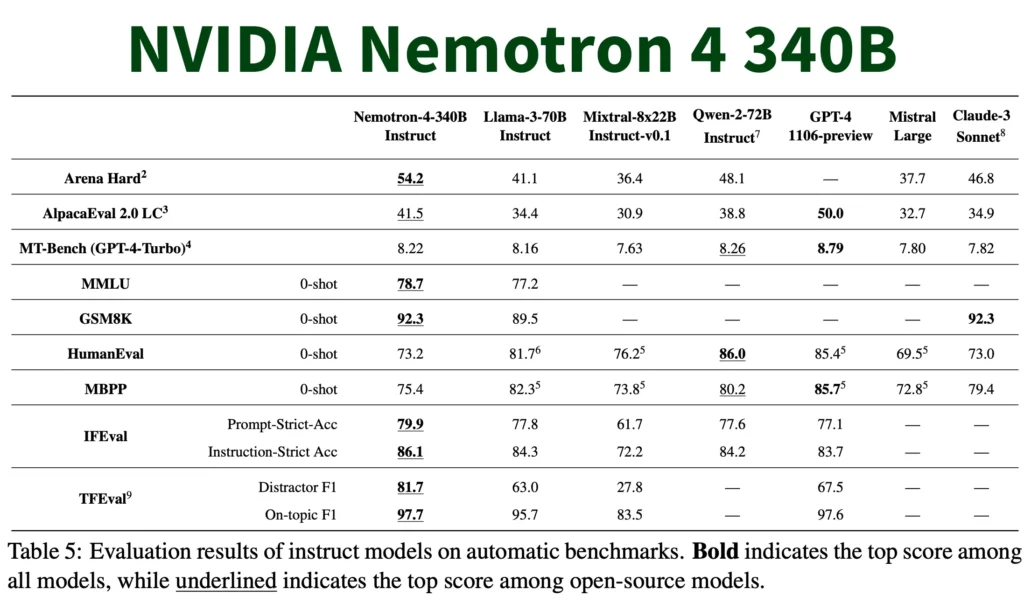
Image Credits: Nvidia
Read More: What is the Role of Processors in Artificial Intelligence (AI) Revolution – techovedas
Potential Uses of Nemotron-4 340B
Here are some advantages that have researchers buzzing:
- Reduced Bias: Real-world data can be riddled with biases that inadvertently get woven into the fabric of LLMs. Synthetic data generation allows for more controlled environments, mitigating the risk of biased training data.
- Focus on Specific Tasks: Nemotron-4 340B allows researchers to tailor the generated data to a specific task.
- Privacy by Design: Synthetic data generation eliminates the need to harvest real-world data, which can raise privacy concerns. This opens doors for training LLMs on sensitive topics without compromising individual privacy.
Follow us on Linkedin for everything around Semiconductors & AI
Conclusion
The release of Nemotron-4 340B marks a significant turning point in AI development. By empowering researchers and developers with the ability to generate their own synthetic data, NVIDIA has unlocked a treasure trove of potential. We can expect to see a new wave of innovation, with LLMs pushing the boundaries of what’s possible across various fields.







