Introduction
All AI systems are not created equal. Some are more powerful, efficient, and versatile than others. One of the key factors that determines the performance of an AI system is the architecture of its neural network, which is the core component that processes data and learns from it-Transformers. 
In this article, we will explore one of the most advanced and influential neural network architectures in AI:The Transformer. No, not the robots that can turn into cars or planes, but the ones that can transform words into meanings and meanings into words. In this article, I will explain to you what Transformers are, how they work, and why they are so awesome.
Follow us on LinkedIn for everything around Semiconductors & AI
What are Transformers?
The Transformer architecture was introduced in 2017 by a team of researchers from Google in a paper titled “Attention Is All You Need”. The paper proposed a new way of building neural networks for NLP tasks, such as machine translation, text summarization, and question answering.
In AI, a transformer refers to a type of neural network architecture primarily used in natural language processing (NLP) tasks. It’s known for its effectiveness in handling sequential data, like sentences or time-series data. The transformer model, introduced by Vaswani et al. in the paper “Attention is All You Need,” relies heavily on attention mechanisms to draw global dependencies between input and output.
Here’s an analogy to explain transformers:
Imagine you’re a student writing an essay. Each word in your essay is like a person in a crowded room. Now, let’s say you want to revise your essay to improve coherence and flow. Instead of trying to focus on every single person in the room at once (like in traditional neural networks), you’re a “transformer.” You have this magical ability to identify and focus on the most relevant people (words) in the room (sentence), regardless of their order. You do this by paying attention to certain key factors, like the importance of each person’s contribution to the topic or how well they connect with each other. By selectively attending to these key factors, you can efficiently revise your essay to make it more cohesive and understandable.
Transformers are especially good at dealing with sequential data, which means data that has a certain order or sequence, such as words in a sentence, notes in a song, or frames in a video. Transformers can learn the patterns and relationships in sequential data and use them to create new data or perform tasks.
How do Transformers work?
Transformers operate through a specialized technique known as attention. This technique allows them to focus on the crucial or relevant elements of the data while disregarding the irrelevant parts.
For instance, when you engage with a narrative, you aren’t required to retain every single word or detail.
Instead, you concentrate on the principal characters, events, and emotions. Attention helps you focus on what matters and understand the story better.
Transformers use attention to process sequential data in two steps: encoding and decoding. Encoding involves converting input data, such as a sentence or an image, into a sequence of numbers that reflect its meaning.
This process captures the essence of the input data in numerical form. Decoding, on the other hand, entails reversing this transformation.
It converts the sequence of numbers back into the original output data, like another sentence or an image, which corresponds to the input.
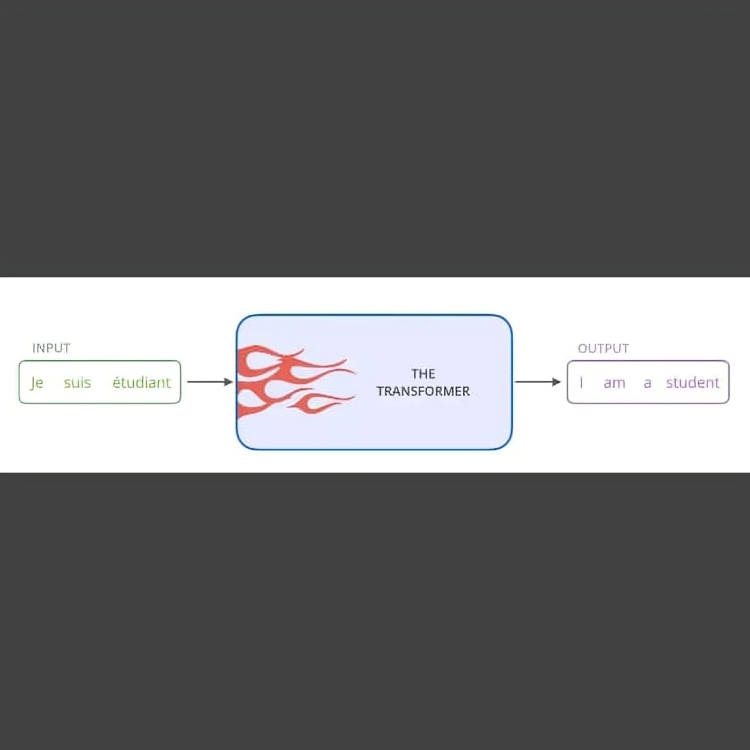
To illustrate, suppose you aim to translate a sentence from English to French. Encoding would translate the English sentence into a sequence of numbers, while decoding would interpret this sequence of numbers to generate the French sentence.
Read more:SK Hynix to Unveil 16-layer HBM3E technology for the first time at ISSCC 2024 – techovedas
What is Self-Attention?
Transformers use a special kind of attention called self-attention, which means they can pay attention to themselves.
This means they can compare different parts of the data and see how they are related to each other.
For example, when you read a sentence, you can use self-attention to see how each word is related to the other words in the sentence, such as who is doing what, or what is describing what. Self-attention helps you understand the structure and meaning of the sentence better.
Transformers use self-attention in both encoding and decoding, but in different ways. In encoding, self-attention helps Transformers learn the meaning of the input data by looking at all the parts of the data at once, instead of one by one.
This makes Transformers faster and more efficient than other machines that need to process the data in a fixed order. In the decoding process, self-attention plays a crucial role in Transformers.
It enables them to generate the output data by considering not only the input data but also the output data generated so far. This differs from other machines, which typically rely solely on the input data for generating output. By incorporating both input and output data, Transformers enhance their accuracy and consistency.
What are some of the famous Transformer models?
Since the introduction of the Transformer architecture in 2017, many researchers and companies have developed and improved various Transformer models for different purposes and domains. Here are some of the most famous and influential Transformer models that have been created so far:
- BERT: BERT stands for Bidirectional Encoder Representations from Transformers. Google developed a language model in 2018 that can learn from both left and right contexts of a word, making it more powerful and versatile than previous models. Various NLP tasks, such as text classification, sentiment analysis, question answering, and more, can fine-tune BERT.
- GPT-3: GPT-3 is the language model developed by OpenAI in 2020. It is based on the Transformer decoder and can generate coherent and diverse texts on any given topic or prompt. GPT-3 is trained on huge amounts of text data from the internet, such as Wikipedia, news articles, books, and social media posts. GPT-2 and GPT-3 have shown remarkable abilities, such as writing essays, poems, stories, code, lyrics, and even generating fake news and deepfakes.
Conclusion
In this article, we have learned about the Transformer architecture and its impact on AI.The Transformer architecture introduces a groundbreaking method for building neural networks.
It harnesses attention mechanisms to extract valuable insights from data more effectively and efficiently.
The versatility of this architecture is clearly evident through its extensive adoption across diverse artificial intelligence domains.
These include natural language processing (NLP), computer vision, speech recognition, and time series forecasting.
Moreover, we have delved into several renowned Transformer models crafted by developers for multifarious applications, including BERT and GPT-3. These models exemplify the transformative impact of the Transformer architecture on advancing AI capabilities across different fields.