
Introduction:
In recent years, Large Language Models (LLMs) have revolutionized the field of artificial intelligence, enabling remarkable advancements in natural language processing tasks. These models, such as GPT-3 and BERT, have demonstrated extraordinary capabilities in generating human-like text and understanding complex linguistic patterns. However, lurking beneath their impressive performance lies a significant challenge: the black box problem.
Follow us on LinkedIn for everything around Semiconductors & AI
Understanding the Black Box Problem
The black box problem refers to the inherent opacity in the decision-making process of LLMs. Unlike traditional software systems where developers can trace the logic behind outputs, LLMs operate as inscrutable entities, making it difficult to comprehend how they arrive at their conclusions. This lack of transparency poses several challenges and ethical concerns, particularly in critical applications such as healthcare, finance, and law.
Analogy
The “black box problem” in large language models (LLMs) can be likened to trying to understand how a magic trick works. Imagine you’re watching a magician perform a seemingly impossible trick. From the outside, you can observe the magician’s actions and the final outcome, but you can’t see inside the black box of their mind to understand the intricate mechanisms or algorithms they’re using to achieve the trick.
Similarly, with LLMs like ChatGPT, users input text and receive responses, but the inner workings of the model—how it processes language, generates responses, or makes decisions are hidden from view. Just like the magician’s trick, while we can see the input and output, the internal processes remain opaque, hence the term “black box.” This lack of transparency can raise concerns about biases, decision-making processes, and overall understanding of the model’s functioning.
Read More: What are Large Language Models? – techovedas
Challenges Posed by the Black Box Problem
Flawed Decision Making:
Without visibility into the internal workings of LLMs, it becomes challenging to identify biases, errors, or logical inconsistencies in their outputs. This can lead to erroneous decisions with far-reaching consequences, especially in fields where accuracy is paramount.
For example, in healthcare, an LLM diagnosing patients may inadvertently overlook critical symptoms due to biases in its training data. To address this, efforts are underway to develop techniques that provide insights into how LLMs make decisions, enabling better scrutiny and validation of their outputs.
Limited Adaptability:
The opacity of LLMs hinders their adaptability to diverse contexts and tasks. Models trained on specific datasets may struggle to generalize to new scenarios or adjust their behavior based on evolving requirements.
For instance, an LLM trained on news articles may struggle to comprehend medical documents, limiting its usefulness in healthcare applications. To mitigate this challenge, researchers are exploring methods for improving the robustness and flexibility of LLMs, such as transfer learning and domain adaptation techniques.
Bias and Knowledge Gaps:
LLMs are susceptible to biases present in their training data, which can perpetuate societal inequalities or produce inaccurate results.Moreover, their proficiency in niche topics may be misleading, leading to overconfident but incorrect outputs.
For example, an LLM trained on historical texts may inadvertently reinforce gender or racial biases in its generated text. Addressing bias and knowledge gaps requires a multifaceted approach, including diverse and representative training data, algorithmic fairness measures, and continuous monitoring and evaluation of model performance.
Read More: 5 Free AI Courses to Empower Your Career by Google – techovedas
Legal and Ethical Accountability:
The opaque nature of LLMs raises questions of legal liability and ethical accountability. If an AI system makes a faulty decision resulting in harm, determining responsibility becomes challenging due to the lack of transparency.
This legal uncertainty can hinder the adoption of LLMs in critical domains such as healthcare and law. To address this, there is a growing emphasis on developing frameworks and standards for responsible AI development and deployment, including guidelines for transparency, fairness, and accountability.
Trust Issues:
Transparency is essential for fostering trust in AI systems, particularly in sensitive applications like healthcare and finance. Users and regulators need assurances that these models operate fairly and without hidden biases.
Without transparency, users may hesitate to rely on LLMs for critical decision-making tasks, undermining their potential benefits. To build trust, developers must prioritize transparency and engage stakeholders in meaningful discussions about the risks and limitations of LLMs, as well as the measures taken to mitigate them.
Emerging Solutions for Transparency
Despite these challenges, researchers are actively developing techniques to enhance the transparency of LLMs. Two prominent approaches are Local Interpretable Model-agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP).
LIME
LIME (Local Interpretable Model-agnostic Explanations) is a technique used to interpret the predictions of complex machine learning models, such as large language models. It works by generating locally faithful explanations for individual predictions, helping users understand how the model arrives at its decisions. LIME creates simplified, interpretable models around specific instances to shed light on the black box nature of complex models.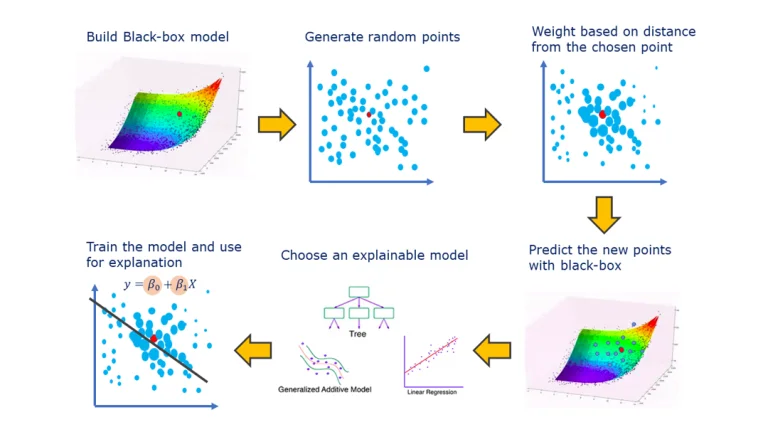
SHAP
SHAP, short for Shapley Additive Explanations, is a method used in machine learning to explain the output of a model by attributing the contribution of each feature to the prediction. It calculates the importance of features based on their impact on model output across all possible combinations, providing insights into the model’s decision-making process.
Additionally, researchers are exploring intervention-based methods and counterfactual approximation techniques to provide causal explanations for LLM predictions. These emerging solutions hold promise for improving the interpretability and accountability of LLMs, paving the way for more transparent and trustworthy AI systems.
Read More: 5 FREE Courses on AI and ChatGPT to Take You From 0-100 – techovedas
Conclusion
The black box problem in LLMs presents formidable challenges, but it also sparks innovation and drives progress in the field of AI transparency. With ongoing research and development efforts, we can overcome these obstacles and pave the way for a future where AI systems are transparent, accountable, and ultimately beneficial to society. Transparency is not just a technical requirement but a fundamental aspect of building trust in AI systems and ensuring their responsible deployment in real-world applications. By prioritizing transparency and embracing emerging solutions, we can unlock the full potential of LLMs while minimizing the risks associated with their use.


